Your Data Is Their Training Set: How AI Companies Are Quietly Bypassing Privacy Laws
As AI companies scramble to feed their models, the boundaries of consent and legality are being quietly erased. From pirated books to scraped user content, your private data may already be part of an AI’s training set — without your knowledge or permission. This piece unpacks how data scarcity is driving AI giants to bypass privacy laws, and why safeguarding your information has never been more critical.
 Donald Trump and OpenAI's Sam Altman (Image
credit: Andrew Harnik / Getty Images)
Donald Trump and OpenAI's Sam Altman (Image
credit: Andrew Harnik / Getty Images)
AI’s Data Crisis: Scarcity Breeds Desperation
Artificial intelligence companies are facing an unprecedented challenge: they’re running out of high-quality data to train their models. The early days of large language models (LLMs) were fueled by vast swaths of publicly available internet text, but that well is drying up fast. According to researchers at Epoch AI, by 2028 the supply of public online text will no longer be sufficient to meet the growing demands of AI systems.1
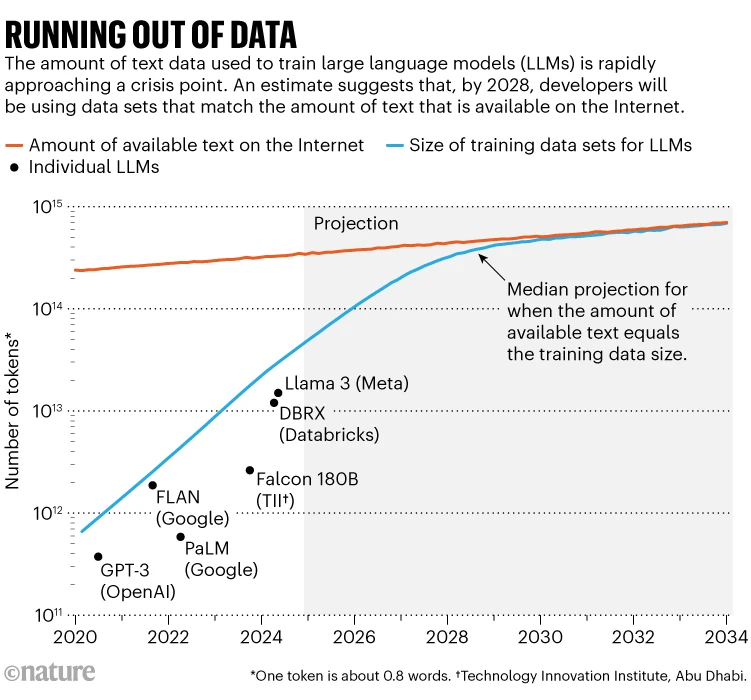 Running out of data (Source: Nature)
Running out of data (Source: Nature)
This scarcity has pushed leading AI companies to explore unconventional — and increasingly controversial — sources of data. With privacy laws tightening and conventional datasets plateauing in value, the industry is now venturing into ethically murky territory.
The Value of High-Quality Training Data
In the AI era, data is more valuable than gold — especially clean, diverse, high-quality data that reflects real-world complexity. Yet, ironically, the success of generative AI has begun to corrupt the very resource it depends on. The internet is becoming saturated with AI-generated content, creating a feedback loop where models train on synthetic content produced by earlier iterations of themselves. This phenomenon, known as model autophagy disorder1, leads to degraded performance and hallucinations.
As premium data sources dwindle and the cost of licensing legitimate content skyrockets, developers are left with a dangerous incentive: to ignore privacy boundaries in pursuit of model improvements.
Meta’s Mass Piracy: Torrenting the Literary World
Recently unsealed court documents2 revealed that Meta, the parent company of Facebook and Instagram, secretly downloaded over 160 terabytes of pirated books from repositories like LibGen and Z-Library. These shadow libraries contain millions of copyrighted works — many of which are still under strict intellectual property protection.
Meta employees themselves expressed concern in internal emails, noting that "torrenting from a corporate laptop doesn’t feel right"3. Despite this, the company proceeded, modifying its torrenting configurations to reduce detectable file sharing (or “seeding”) and evade legal scrutiny. Critics argue this constitutes one of the largest acts of corporate data piracy in history.
The justification? Fair use — a legal grey area AI companies increasingly rely on. But fair use is not a blanket exemption, especially when training data includes copyrighted or sensitive personal content.
OpenAI and Google Admit to Using Unlicensed Data
In a rare moment of candor, OpenAI and Google4 recently urged the U.S. government to loosen copyright restrictions on AI training. Their proposals advocate for the legal right to use copyrighted material without explicit permission — a bold move that seems to acknowledge previous practices.
OpenAI’s argument is blunt: if American companies are forced to comply with restrictive data laws while China is not, the U.S. risks losing the global AI race5. It’s an appeal to national security — and a tacit admission that much of today’s AI may have been built on unauthorized data.
These companies also hint at tapping into user-generated content: private messages, videos, and audio recordings. While some platforms, like Zoom, have pledged not to use customer data for AI, others remain vague. The line between what is “public” and what is “scrapable” is being redrawn without public input.
Is Synthetic Data the Answer — or Another Risk?
To navigate the data scarcity crisis, many companies are turning to synthetic data6: artificially generated datasets designed to mimic real-world patterns without exposing personally identifiable information (PII). In theory, synthetic data offers a privacy-preserving alternative that supports model training without infringing on rights.
However, this approach is not without risk. Improperly generated synthetic data can introduce bias, degrade model performance, or inadvertently re-identify individuals if based too closely on original data. The United Nations University recommends strong safeguards and clear documentation to mitigate these concerns — but adoption of such guidelines is uneven.
Moreover, under regulations like the EU’s General Data Protection Regulation (GDPR), even synthetic data may fall under scrutiny if it is derived from identifiable personal information. While anonymization techniques help, only true anonymization — not pseudonymization — can fully exempt data from GDPR obligations.
Conclusion: If Laws Can’t Protect You, Only Privacy-First Design Will
As AI companies stretch legal and ethical boundaries in their hunt for training data, the privacy of individuals is becoming collateral damage. The lack of transparency around how models are trained, combined with the erosion of consent and data ownership, represents a growing threat to personal and institutional privacy.
The takeaway is clear: organizations must act now to safeguard their data. This means implementing robust anonymization frameworks, ensuring regulatory compliance, and pushing back against opaque AI data practices. Because in the AI arms race, if your data isn't protected — it’s already being used.
Footnotes
- The AI revolution is running out of data. What can researchers do? | Nature ↩ ↩2
- Meta claims torrenting pirated books isn’t illegal without proof of seeding | Ars Technica ↩
- “Torrenting from a corporate laptop doesn’t feel right”: Meta emails unsealed | Ars Technica ↩
- OpenAI and Google ask the government to let them train AI on content they don’t own | The Verge ↩
- OpenAI urges U.S. to allow AI models to train on copyrighted material | NBC News ↩
- Synthetic data is the future of Artificial Intelligence | Moez Ali ↩


