Ihre Daten sind ihr Trainingsmaterial: Wie KI-Unternehmen stillschweigend Datenschutzgesetze umgehen
Während KI-Unternehmen fieberhaft versuchen, ihre Modelle zu füttern, werden die Grenzen von Einwilligung und Legalität leise verwischt. Von raubkopierten Büchern bis hin zu aus dem Internet gesammelten Nutzerinhalten – Ihre privaten Daten könnten bereits Teil eines KI-Trainingssets sein, ohne Ihr Wissen oder Ihre Zustimmung. Dieser Beitrag zeigt auf, wie Datenknappheit KI-Giganten dazu bringt, Datenschutzgesetze zu umgehen, und warum der Schutz Ihrer Informationen heute wichtiger denn je ist.
 Donald Trump und OpenAI's Sam Altman (Image
credit: Andrew Harnik / Getty Images)
Donald Trump und OpenAI's Sam Altman (Image
credit: Andrew Harnik / Getty Images)
Die Datenkrise der KI: Knappheit erzeugt Verzweiflung
KI-Unternehmen stehen vor einer noch nie dagewesenen Herausforderung: Ihnen gehen qualitativ hochwertige Daten für das Training ihrer Modelle aus. In den Anfangstagen grosser Sprachmodelle (LLMs) wurden diese durch riesige Mengen an öffentlich zugänglichen Internettexten gespeist – doch diese Quelle versiegt rapide. Laut Forschenden von Epoch AI wird bis 2028 das Angebot an öffentlichem Online-Text nicht mehr ausreichen, um den steigenden Bedarf von KI-Systemen zu decken.1
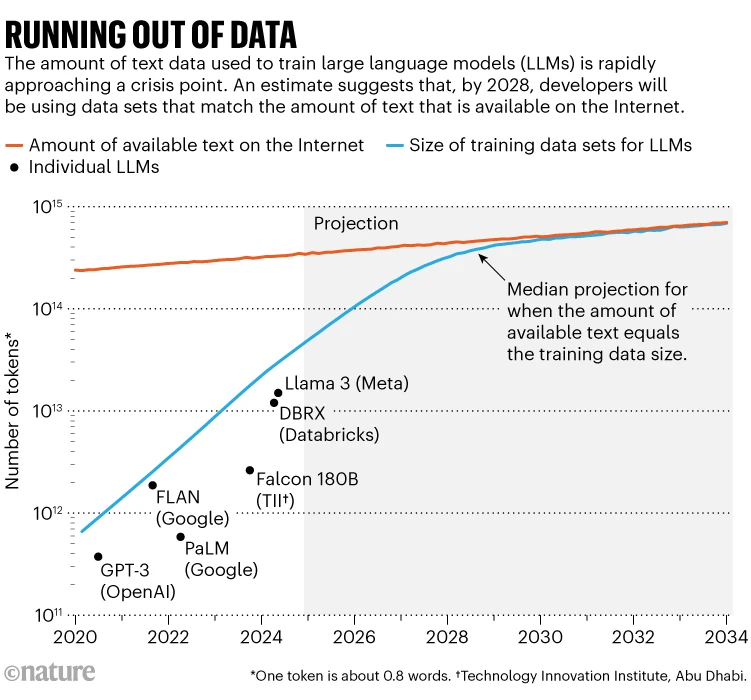 Running out of data (Source: Nature)
Running out of data (Source: Nature)
Diese Knappheit treibt führende KI-Unternehmen dazu, unkonventionelle – und zunehmend umstrittene – Datenquellen zu erschliessen. Mit immer strengeren Datenschutzgesetzen und der abnehmenden Wertigkeit konventioneller Datensätze begibt sich die Branche in ethisch fragwürdiges Terrain.
Der Wert hochwertiger Trainingsdaten
Im KI-Zeitalter sind Daten wertvoller als Gold – insbesondere saubere, vielfältige und qualitativ hochwertige Daten, die die Komplexität der realen Welt abbilden. Ironischerweise beginnt jedoch gerade der Erfolg generativer KI, diese essenzielle Ressource zu verfälschen. Das Internet wird zunehmend mit KI-generierten Inhalten überschwemmt, was zu einem Rückkopplungseffekt führt: Modelle trainieren auf synthetischen Inhalten, die von früheren Versionen ihrer selbst erstellt wurden. Dieses Phänomen, bekannt als Model Autophagy Disorder1, führt zu Leistungsabfall und Halluzinationen.
Da hochwertige Datenquellen schwinden und die Kosten für lizenzierte Inhalte in die Höhe schiessen, entsteht ein gefährlicher Anreiz für Entwickler: Datenschutzgrenzen zu missachten, um Modellverbesserungen zu erzielen.
Metas Massenpiraterie: Das Torrenting der literarische Welt
Kürzlich veröffentlichte Gerichtsunterlagen2 zeigen, dass Meta, die Muttergesellschaft von Facebook und Instagram, heimlich über 160 Terabyte raubkopierter Bücher von Repositories wie LibGen und Z-Library heruntergeladen hat. Diese Schattenbibliotheken enthalten Millionen urheberrechtlich geschützter Werke – viele davon stehen noch unter strengem Schutz geistigen Eigentums.
Selbst Meta-Mitarbeitende äusserten in internen E-Mails Bedenken und bemerkten: „Torrents von einem Firmenlaptop herunterzuladen, fühlt sich nicht richtig an“3. Trotzdem machte das Unternehmen weiter und passte seine Torrent-Einstellungen an, um das Teilen von Dateien (das sogenannte „Seeding“) zu minimieren und rechtlicher Aufmerksamkeit zu entgehen. Kritiker bezeichnen dies als einen der grössten Fälle von unternehmensgetriebener Datenpiraterie in der Geschichte.
Die Rechtfertigung? Fair Use – ein juristisches Graufeld, auf das sich KI-Unternehmen zunehmend verlassen. Doch Fair Use ist keine pauschale Ausnahme, insbesondere wenn Trainingsdaten urheberrechtlich geschützte oder sensible persönliche Inhalte enthalten.
OpenAI und Google geben zu: Nutzung unlizensierter Daten
In einem seltenen Moment der Offenheit forderten OpenAI und Google4 kürzlich die US-Regierung auf, Urheberrechtsbestimmungen für das KI-Training zu lockern. Ihre Vorschläge plädieren für das gesetzliche Recht, urheberrechtlich geschütztes Material ohne ausdrückliche Genehmigung nutzen zu dürfen – ein kühner Schritt, der auf frühere Praktiken hindeutet.
OpenAIs Argumentation ist unverblümt: Wenn amerikanische Unternehmen sich an restriktive Datenschutzgesetze halten müssen, während dies in China nicht gilt, droht der USA ein Rückstand im globalen KI-Wettlauf5. Es ist ein Appell an die nationale Sicherheit – und ein stilles Eingeständnis, dass viele heutige KI-Modelle auf unautorisierten Daten aufgebaut sein könnten.
Auch die Nutzung nutzergenerierter Inhalte wird angedeutet: private Nachrichten, Videos und Tonaufnahmen. Während Plattformen wie Zoom zugesichert haben, Kundendaten nicht für KI zu verwenden, bleiben andere vage. Die Grenze zwischen dem, was „öffentlich“ und dem, was „abgreifbar“ ist, wird ohne öffentliche Mitbestimmung neu gezogen.
Sind synthetische Daten die Lösung – oder nur ein neues Risiko?
Um der Datenknappheit zu begegnen, setzen viele Unternehmen auf synthetische Daten6: künstlich generierte Datensätze, die reale Muster nachahmen sollen, ohne personenbezogene Informationen offenzulegen. In der Theorie bieten synthetische Daten eine datenschutzfreundliche Alternative, die Modelltraining ohne Rechtsverletzung ermöglicht.
Doch dieser Ansatz birgt Risiken. Falsch generierte synthetische Daten können Vorurteile von Modellen verstärken, die Modellleistung beeinträchtigen oder – bei zu grosser Nähe zum Original – sogar Einzelpersonen ungewollt re-identifizierbar machen. Die Universität der Vereinten Nationen empfiehlt deshalb strenge Schutzmassnahmen und transparente Dokumentation – deren Umsetzung ist jedoch uneinheitlich.
Zudem könnten laut Regelungen wie der EU-Datenschutzgrundverordnung (DSGVO) selbst synthetische Daten unter Prüfstand geraten, wenn sie auf identifizierbaren Informationen basieren. Während Anonymisierungstechniken helfen, bietet nur echte Anonymisierung – nicht Pseudonymisierung – vollständige DSGVO-Befreiung.
Fazit: Wenn Gesetze nicht schützen, hilft nur datenschutzorientiertes Design
Da KI-Unternehmen gesetzliche und ethische Grenzen dehnen, wird die Privatsphäre Einzelner zunehmend zum Kollateralschaden. Die mangelnde Transparenz darüber, wie Modelle trainiert werden, kombiniert mit dem Verlust von Einwilligung und Datenhoheit, stellt eine wachsende Bedrohung für persönliche und institutionelle Privatsphäre dar.
Die Lehre daraus ist klar: Organisationen müssen jetzt handeln, um ihre Daten zu schützen. Das bedeutet robuste Anonymisierungsverfahren einzuführen, Regelkonformität sicherzustellen und undurchsichtige KI-Datenpraktiken in Frage zu stellen. Denn im KI-Wettrüsten gilt: Wenn Ihre Daten nicht geschützt sind – werden sie bereits genutzt.
Footnotes
- The AI revolution is running out of data. What can researchers do? | Nature ↩ ↩2
- Meta claims torrenting pirated books isn’t illegal without proof of seeding | Ars Technica ↩
- “Torrenting from a corporate laptop doesn’t feel right”: Meta emails unsealed | Ars Technica ↩
- OpenAI and Google ask the government to let them train AI on content they don’t own | The Verge ↩
- OpenAI urges U.S. to allow AI models to train on copyrighted material | NBC News ↩
- Synthetic data is the future of Artificial Intelligence | Moez Ali ↩


